所谓处理器架构,或者处理其编程架构,是指一整套的硬件结构,以及与之相适应的工作状态
Intel32微处理器架构简称IA-32,以8086处理器为基础发展而来
8086有20根地址线,可寻址1MB内存。内部寄存器16位,无法在程序中访问整个1MB内存,所以,它是第一款支持内存分段模型的处理器。8086处理器只有一种工作模式,即实模式
32位的处理器有32根地址线,数据线的数量是32根或64根。它可以访问2^32,即4GB的内存,每次可读写连续的4字节或8字节,称为双字或4字访问
IA-32架构的基本执行环境
寄存器的扩展
在16位处理器内,有8个通用寄存器AX、BX、CX、DX、SI、DI、BP和SP,其中,前4个还可以拆分成两个独立的8位寄存器使用,即AH、AL、BH、BL、CH、CL、DH和DL
32位处理器在16位处理器的基础上,扩展了这8个通用寄存器的长度
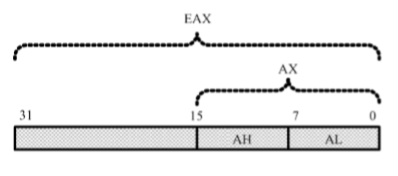
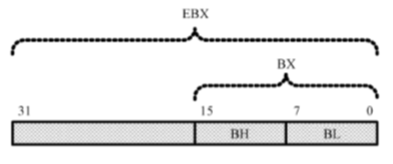
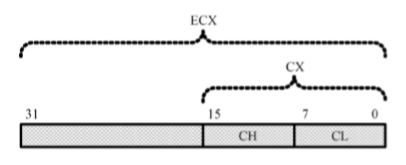
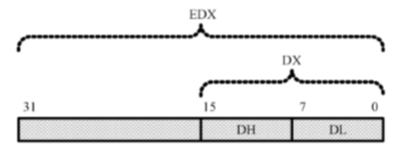
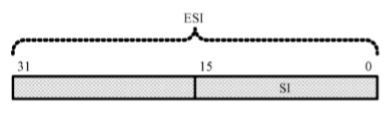
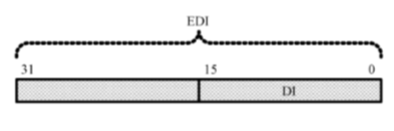
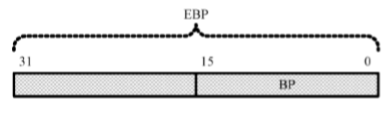
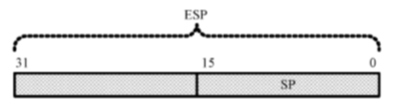
为了在汇编语言中使用经过扩展的寄存器,需要给它们重命名,分别为EAX、EBX、ECX、EDX、ESI、EDI、ESP和EBP。可以在程序中使用这些寄存器,即使在实模式中
指令的源操作数与目的操作数必须具有相同的长度,个别特殊用途的指令除外
1 | mov eax,f0000005h |
1 | mov eax,cx ;错误的汇编指令,位数不符 |
32位通用寄存器的高16位是不可独立使用的,但低16位保持同16位处理器的兼容性
1 | mov ah,02h |
32位处理器有自己的32位工作模式。在32位保护模式下,可以完全、充分的发挥处理器的性能,同时,处理器可以使用它全部的32根地址线,能够访问4GB的内存
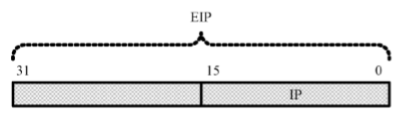
32位处理器扩展了IP,使之达到32位,即EIP
当它工作在16位模式下,使用16位IP;工作在32位模式下,使用全部的32位EIP
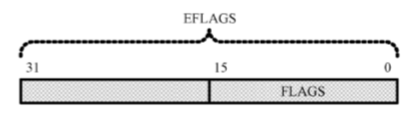
16位处理器中,标志寄存器FLAGS为16位,在32位处理器中,扩展到32位,低16位和原先保持一致
在32位模式下,对内存的访问从理论上来说不再需要分段,因其有32根地址线,可以自由访问4GB内存的任何一个内存位置。但IA-32架构的处理器是基于分段模型的,则32位处理器依然需要以段为单位访问内存,只分一个段,段的基地址为00000000h,段的长度为4GB。在这种情况下,可视为不分段,即平坦模型
在16位模式下,一个程序可以自由的访问不属于它的内存位置,甚至可以对那些地方的内容进行修改,这是不安全的。在32位模式下,处理器要求在加载程序时,先定义该程序所拥有的段,然后允许使用这些段。定义段时,除了基地址外,还附加了段界限、特权级别、类型的等属性。当程序访问一个段时,处理器将用固件实施各种检查工作,以防止对内存的违规访问
在32位模式下。传统的段寄存器,如CS、SS、DS、ES,保存的不再是16位段地址,而是段的选择子,即用于选择所要访问的段,它的新名称为段选择器。除段选择器外,每个段寄存器还包括一个64位的不可见部分,称为描述符高速缓存器,里面有段的基地址和各种访问属性,这部分内容不可见,由处理器自动使用

32位处理器增加了两个额外的段寄存器FS和GS
基本的工作模式
8086具有16位的段寄存器、指令寄存器和通用寄存器,称为16位的处理器。尽管8086可以访问1MB的内存,但只能分段进行,而且由于只使用16位的段内偏移量,故段的长度最大只能是64KB
80286处理器段寄存器16位,而且只能使用16位的偏移地址,在实模式下只能使用64KB的段;尽管它有24根地址线,理论上可以访问2^24,即16MB的内存,但依然只能分为多个段来进行
80286处理器第一次提出了保护模式的概念,在保护模式下,段寄存器中保存的不再是段地址,而是段选择子,真正的段地址位于段寄存器的描述符高速缓存中,是24位的。因此,运行在保护模式下的80286处理器可以访问全部的16MB内存
80386处理器的寄存器是32位的,而且拥有32根地址线,可以访问2^32,即4GB的内存
在保护模式下,所有的32位处理器都可以访问多达4GB的内存,它们可以工作在分段模式下,每个段的基地址为32位的,段内偏移为32位的,因此,段的长度不受限制。32位保护模式兼容80286的16位保护模式
32位处理器提供虚拟8086模式(V86模式),在这种模式下,IA-32处理器被模拟成多个8086处理器并行工作。V86模式是保护模式的一种,可以在保护模式下执行多个8086程序
线性地址
IA-32处理器编程时,访问内存时,需提供段地址和偏移量
段的管理由处理器的段部件负责进行,段部件将段地址和偏移地址相加,得到访问内存的地址,一般来说,段部件产生的地址就是物理地址
IA-32处理器在多任务环境下,对程序内存进行分配和回收,会产生内存碎片,IA-32处理器支持分页功能,分页功能将物理内存空间划分为逻辑上的页。页的大小是固定的,一般为4KB,通过分页,可以简化内存管理
当分页功能开启时,段部件产生的地址就不再是物理地址了,而是线性地址,线性地址要经过页部件转换后,才是物理地址
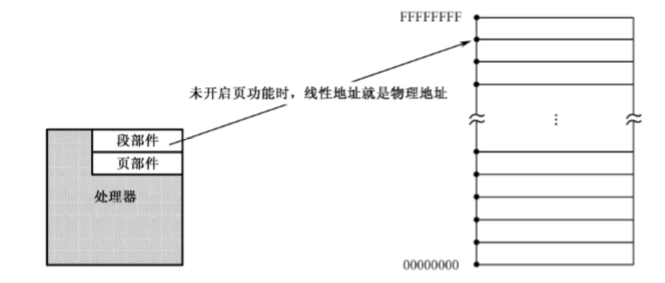
线性地址的概念用来描述任务的地址空间。IA-32处理器的每个任务都拥有4GB的虚拟内存空间,是一段长4GB的平坦空间,叫做线性地址空间。相应的,由段部件产生的地址,就对应着线性地址空间上的每一个点,就是线性地址
现代处理器的结构和特点
流水线
8086时代,处理器就存在指令预取队列。当指令执行时,若总线空闲(无访问内存的操作),就可以在指令执行的同时预取指令并提前译码,可以大大加快程序的执行速度
为提高处理器的执行效率和速度,可以将一条指令的执行过程分解为若干个细小的步骤,并分配给相应的单元来完成。各个单元的执行是独立的、并行的。如此一来,各个步骤的执行在时间上就会重叠起来,这种执行指令的方法就是流水线技术
3级流水线:
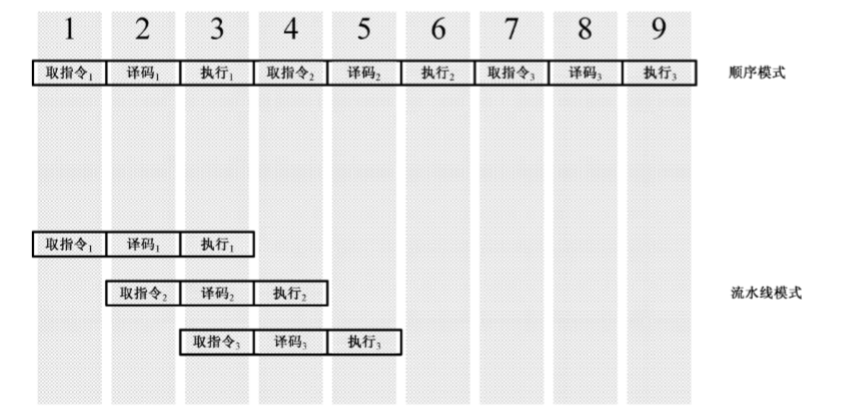
一般来说,流水线的效率受执行时间最长的那一级的限制
,要缩短各级的执行时间,就必须让每一级的任务减少,与此同时,需要将一些复杂的任务再进行分解
高速缓存
因为需要等待内存和硬盘这样的慢速设备,处理器便无法全速运行。为缓解这一矛盾,高速缓存应运而生。高速缓存是处理器和内存之间的一个静态存储器,容量较小,但速度可以与处理器匹配
程序运行时的局部性原理:程序常常访问最近刚刚访问过的指令和数据,或者与它们相邻的指令和数据
利用程序运行时的局部性原理,可以把处理器正在访问和即将访问的指令和数据块从内存调入高速缓存中。当处理器要访问内存时,首先检索高速缓存,若要访问的内容已在高速缓存中,那么可以用极快的速度直接从高速缓存中取得,称为命中;否则,称为不中。在不中的情况下,处理器在取得需要的内容之前必须重新装载高速缓存,而不只是直接到内存中取得所需要的内容
高速缓存的转载以块为单位,包括装载所需数据的邻近内容。为此,需要额外的时间来等待块从内存载入高速缓存,在该过程中损失的时间称为不中惩罚
在一些复杂的处理器内部,会存在多级高速缓存,分别应用于各个独立的执行部件
乱序执行
为实现流水线技术,需要将指令拆分为更小的可独立执行部分,即拆分成微操作
例:
1 | add [mem],eax |
可拆分为三个微操作,一个从内存中读数据,一个执行相加动作,一个用于将相加的结果写回内存中
一旦将指令拆分为微操作,处理器就可以在必要的时候乱序执行程序
1 | mov eax,[mem1] |
指令add eax,[mem2]可以拆分为两个微操作。在执行逻辑左移指令的同时,处理器可以提前从内存中读取mem2的内容。典型的,若数据不在高速缓存中(不中)时,那么处理器在获取mem1的内容后,会立即开始获取mem2的内容,与此同时,shl指令的执行早就开始了
寄存器重命名
1 | mov eax,[mem1] |
上述代码中,前三条与后三条进行了两件互不相关的事。但是在代码中使用了相同的寄存器。此时,处理器为最后三条指令使用了另一个不同的临时寄存器,用于左移指令和加法指令可以并行处理
IA-32架构的处理器只有8个32位的通用寄存器。不过,在处理器的内部,却有大量的临时寄存器可用,处理器可以重命名这些寄存器以代表一个逻辑寄存器
寄存器重命名以一种完全自动和非常简单的方式工作。每当指令写逻辑寄存器时,处理器就为那个逻辑寄存器分配一个新的临时寄存器
1 | mov eax,[mem1] |
若mem1的内容在高速缓存中,可立即取得。mem2内容不在高速缓存中。此时,逻辑左移操作可以在加法指令之前开始(使用临时寄存器代替EAX)。
将mem1的内容写入eax后,mem2的内容需要从内存读取,此时,使用临时寄存器存储逻辑左移指令的结果,eax中仍然只是存储mem1的内容,用于使用eax执行完加法指令
若没有寄存器重命名机制,逻辑左移操作将不得不等待从内存中读取mem2的内容到ebx寄存器并进行完加法操作之后才得以执行
在所有操作完成后,那个临时寄存器中存储的eax寄存器的最终结果才被写入真实的eax寄存器,该过程称为引退
所有的通用寄存器,堆栈指针、标志、浮点寄存器,甚至段寄存器都有可能被重命名
分支目标预测
流水线并不是百分之百完美的解决方案。事实上,有很多潜在的因素会使得流水线不能达到最佳效率。典型的情况,若遇到一条转移指令,则后面那些已经进入到流水线的指令就都无效了。即,必须清空流水线,从要转移的目标位置处重新取指令放入流水线
在现代处理器中,流水线操作分为很多步骤,包括取指令、译码、寄存器分配和重命名、微操作排序、执行和引退。指令的流水线处理方式允许处理器同时做很多事情
流水线的最大问题是代码中经常存在分支,流水线越长,处理器在用错误的分支填充流水线时,浪费的时间越多
为解决这个问题,在Pentium Pro处理器上,引入分支预测技术。分支预测的核心问题是:转移是发生还是不会发生,或条件转移指令的条件会不会成立
从统计学的角度来看,有些事情一旦出现,下一次还会出现的概率较大。一个典型的案例就是循环,当循环执行一次后,下一次还会执行,而不是顺序向下执行,事实上,这个预测通常是很准的
在处理器内部,有一个小容量的高速缓存器,叫做分支目标缓存器(BTB),当处理器执行了一条分支语句后,它会在BTB中记录当前指令的地址、分支目标的地址,以及本次分支预测的结果。下一次,在那条转移指令实际执行前,处理器会查找BTB,看有没有最近的转移记录。若可以找到对应的条目,则推测执行和上一次相同的分支,把该分支的指令送入流水线
当该指令实际执行时,若预测是失败的,那么,清空流水线,同时刷新BTB中的记录。代价较大
32位模式的指令系统
32位处理器的寻址方式
在16位处理器上,指令中的操作数可以是8位或者16位的寄存器、指向8位或者16位实际操作数的16位内存地址,以及8位或16位的立即数
16位处理器,使用基址寄存器同变址寄存器,再加上8位或16位偏移量来寻址内存操作数
32位处理器兼容16位处理器的工作模式,可以运行传统的16位代码,但是,它有自己独立的32位运行模式
在32位模式下,默认使用32位宽度的寄存器
1 | mov eax,ebx |
若指令中使用了立即数,那么,默认该数值也是32位的
1 | mov ecx,55h ;ECX<-00000055 |
若指令中的操作数是指向内存单元的地址,那么,该地址默认是32位的段内偏移地址,或称做段内偏移量
1 | mov edx,[mem] ;mem是一个32位的段内偏移地址 |
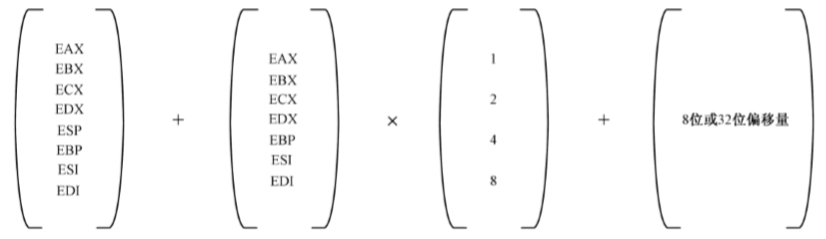
32位处理器的寻址方式可以使用全部的32位通用寄存器作为基址寄存器。同时,还可以再加上一个除ESP之外的32位通用寄存器作为变址寄存器。变址寄存器允许乘以1、2、4或8作为比例因子。最后,还允许加上一个8位或32位的偏移量
操作数大小的指令前缀
每一条处理器指令都可以拥有前缀,例重复前缀(REP/REPE/REPNE)、段超越前缀(ES:)、总线封锁前缀(LOCK)等
前缀是可选的,每个前缀的长度是1字节,每条指令可以拥有1–4个前缀,或者不使用前缀
前缀(如果有的话)的后面是操作码部分。操作码的长度是1–3字节。操作码可以表示指令执行什么操作,同时,操作码还可以指示操作的字长,即数据宽度为字节还是字
操作码之后是操作数类型和寻址方式部分。此部分可选。简单指令不包含此部分,此部分也可以有1–2字节。这部分给出了指令的寻址方式,以及寄存器的类型
指令的最后是立即数和偏移量,可以是1、2或4字节

例:
1 | mov dx,[bx+si+02h] |
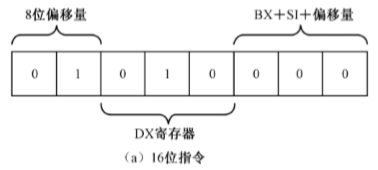
在16位指令编码格式中,内存单元到寄存器的传送指令使用操作码8BH,在8BH之后是1字节的寻址方式和操作数类型部分。第7位和第6位是01,表示使用了基地址变址的寻址方式,且带有8位偏移量;第5–3位为010,指示目的操作数为寄存器DX;位2–0位为000,表示寻址方式为BX+SI+8位偏移量。在该字节之后,是1字节的偏移量02h。因此,这条指令编译后的机器代码为
1 | 8B 50 02 |
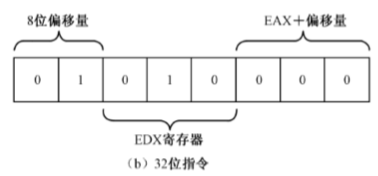
32位处理器使用相同的编码格式,但寻址方式和寄存器的定义不同于16位指令。在32位处理器上,第7位和第6位的值是01,表示使用基址寻址方式,且带有8位偏移量;第5–3位为010,指示目的操作数为寄存器EDX;第2–0位为000,表示寻址方式为EAX+8位偏移量。在该字节之后,是1字节的偏移量02h。因此,同样的机器指令码,却对应不同的32位指令:
1 | mov edx,[eax+02h] |
即,相同的机器指令,在16位模式下和32位模式下的解释和执行效果是不同的
32位处理器可以执行16位的程序。为此,在16位模式下,处理器将所有的指令都看作16位的。
机器指令吗40h在16位模式下的含义:
1 | inc ax |
当处理器在16位模式下运行时,也可以使用32位的寄存器,执行32位的运算。为此,必须使用指令前缀66h来临时改变这种默认状态。因此,当处理器在16位模式下运行时,机器指令码66 40对应的指令不再是inc ax,而是inc eax(16位模式下执行32位指令)
相反的,若处理器运行在32位模式下,处理器默认指令的操作数为32位的,若添加66h指令前缀,用于指示指令是16位的(32位模式执行16位指令)
即,指令前缀66h具有反转当前默认操作数大小的作用
在编写程序的时候,就应考虑到指令的运行环境。为指明程序的默认运行环境,编译器提供伪指令bits,用于指明其后的指令应该被编译成16位还是32位的
1 | bits 16 ;可写作[bits 16] |
16位模式是默认的编译模式,若为指定指令的编译模式,则默认是bits 16的
一般指令的扩展
32位的处理器都拥有32位的寄存器和算术逻辑部件,而且同内存芯片之间的数据通路至少是32位的,因此,所有以寄存器或者内存单元为操作数的指令都被扩充,以适应32位的算术逻辑操作。而且,这些扩展的操作即使是在16位模式下(实模式和16位保护模式)也是可用的
双操作数指令、单操作数指令允许32位操作数
逻辑移动指令,如
shl、shr等,目的操作数也扩展至32位和16位处理器相同,在32位处理器上,逻辑移动指令的源操作数如果是寄存器的话,则依然必须使用
CL。同时,32位处理器在实际执行时,要先将源操作数(在CL寄存器内)同1FH做逻辑与。也就是说,仅保留源操作数的低5位,因此,实际移动的次数最大为31在16位处理器上,
loop指令的循环次数在寄存器CX中。在32位处理器上,如果当前的运行模式是 16 位的,那么,loop指令执行时,依然使用CX寄存器;否则,如果运行在32位模式下,则使用的是ECX寄存器16位处理器中,无符号数乘法指令
mul格式为:1
2mul r/m8 ;AX ← AL×r/m8
mul r/m16 ;DX:AX ← AX×r/m1632位处理器中,除了上述支持外,还支持以下扩展
1
mul r/m32 ;EDX:EAX ← EAX×r/m32
有符号数乘法指令
imul与此相同无符号数和有符号数除法也做了32位扩展
1
2div r/m32
idiv r/m32被除数是64位的,高32位在
EDX寄存器;低32位在EAX寄存器。除数是32位的,位于32位的寄存器或内存单元。指令执行后,32位的商在EAX寄存器,32位的余数在EDX寄存器32位处理器的堆栈操作指令
push和pop也有所扩展,允许压入双字操作数特别是,现在支持立即数压栈操作
1
2
3push imm8 ;操作码为 6A
push imm16 ;操作码为 68
push imm32 ;操作码为 68例:压入字节数据
1
push byte 55h
byte仅仅是给编译器用的,告诉编译器,压入的是字节,而不是用来在编译后的机器指令前添加指令前缀这条指令的16位形式和32位形式是一样的,机器 代码都是
6A 55但是,当它执行时,就不同了。注意,无论在什么时候,处理器都不会真的压入一字节,要么压入字,要么压入双字
在16位模式下,默认的操作数字长是16,处理器在执行时,将该字节的符号位扩展高8位,然后压入堆栈,压栈时使用
SP寄存器,且先将SP的内容减去2。这就是说,实际压入堆栈中的数值是0055h在32位模式下,压入的内容是该字节操作数符号位扩展高24位的结果,即
00000055h。压栈时使用ESP寄存器,且先将ESP的内容减去4。如果压入的是字操作数,则必须用关键字
word来修饰例:压入字数据
1
push word fffbh
在16位模式下,默认的操作数字长是16,处理器在执行时,直接压入该字,压栈时使用
SP寄存器,且先将SP的内容减去2在 32 位模式下,压入的内容是该操作数符号位扩展高16位的结果,即
FFFFFFFBH,压栈时使用ESP寄存器,且先将ESP的内容减去4如果压入的是双字操作数,则必须用关键字
dword来修饰例:压入双字数据
1
push dword fbh
无论是在16位模式下,还是在32位模式下,压入的都是
000000FBH,而且堆栈指针寄存器(SP或者ESP)都先减去4对于实际操作数位于通用寄存器,或者位于内存单元的情况,只能压入字或者双字
指令格式为:
1
2push r/m16
push r/m32如果是寄存器,则可以使用16位或者32位的通用寄存器
如果被压入的16位或者32位操作数位于内存单元中,则必须用关键字
word或者dword修饰,以指示操作数的大小1
2push word [0x2000]
push dword [ecx+esi*2+0x02]无论被压入的数位于寄存器,还是位于内存单元,在16位模式下,如果压入的是字操作数,那么 先将
SP的内容减去2;如果压入的是双字,应当先将SP的内容减去4在32位模式下,如果压入的是字操作数,那么先将
ESP的内容减去2;如果压入的是双字,应当先将ESP的内容减去4段寄存器压入栈
格式:
1
2
3
4
5
6push cs ;机器指令为 0E
push ds ;机器指令为 1E
push es ;机器指令为 06
push fs ;机器指令为 0F A0
push gs ;机器指令为 0F A8
push ss ;机器指令为 16在16位模式下,先将
SP的内容减去2,然后直接压入段寄存器的内容在32位模式下,要先将段寄存器的内容用零扩展到32位,即高16位为全零。然后,将
ESP的内容减去4,再压入扩展后的32位值